
Overview
The only certainty with AI is that AI will get things wrong. This is because the primary statistical tool of AI, machine learning (ML), is a technique for probabilistic decision making. In other words, the algorithms powering ML are designed to fail at least some of the time. In fact, if an AI gets things right for 100% of training examples, it is actually likely that the system is ‘overfitted’ and will not generalize well to new examples. Unlike a physical machine such as an engine, which only fails by mistake, an AI system is intended to fail by design. In fact, allowing AIs to fail makes them more robust in the long run. Designing for errata can open new opportunities for AI to overcome failure, gain knowledge, and ultimately delight users.
When to Fail
Well-designed AIs have intentionally chosen when to be wrong, as well as how wrong to be. It is not true that AI is always as accurate as its data allows—sometimes it is better to be intentionally more inaccurate because not all failure cases should be treated equally[1].
In Yes/No decisions, there are false positives (predicting incorrectly) and false negatives (ignoring incorrectly), which approximately relate to how cautious the algorithm is. If an AI is designed to be cautiously risk-averse, it would try to catch all occurences of the phenomenon, even if that means making many false positive judgments. In an AI is more concerned with making a few winning guesses, it may make many false negative judgments.

Beyond simple binary decisions, algorithms may have to make complex and multi-class decisions. For these, it is important to consider the tradeoff between insufficient (leaving out important details) and unnecessary (containing some incorrect details). Especially in situations like product recommendations, there may be different risks between these failure cases.
Failure By Design
In cases where failure is genuinely undesirable, AI should gracefully account for error cases and mistakes. In some cases, failure is actually perfectly acceptable, such as in creative and artistic cases where accidents are part of the process. In other cases, the system must be amendable or editable, as a false decision could have massive downstream repercussions. An AI made to decide on cancer diagnoses will make a non-negligible amount of errors, and a variety of precautions need to be put in place to safeguard patients. By crafting a design that mitigates failure cases with oversight or review, your system becomes more trustworthy.
In many cases, the system does not completely fail, but fails partially. For example, in transcribing a PDF document to text a system may have a roughly 90% success rate per word, leading to many mistakes scattered through the document. In these partial failure cases, user experience tweaks may improve the system more than algorithmic tuning. For example, users could be asked to review the document and correct errors. In certain systems, such as recommendation engines, users may want to amend the system by giving positive or negative ratings back to the system. These various examples of failure are more than edge cases, but make up a core part of your AI system. Even if failures are ‘low-probability’, they are important to design for, given that extreme cases are typically more memorable (in both positive and negative ways). Seeing failure as a design pattern rather than an aberration allows your AI to more robustly interface with its environment and stakeholders (see Choosing Technologies).
Individually Wrong but Generally Right
The need for AI systems to make mistakes stems in part from the natural ambiguity in complex decisions. If someone were to ask you if a particular image contains a cat, you may genuinely answer with “I don’t know”. Yet when we phrase such a question to an AI, we often require the system to make a best guess for the sake of the task at hand. AI systems must make errors in order to make useful decisions that are accurate most of the time—in other words, not answering “I don’t know” to every question. Unfortunately, most AI-based products and services overstate their own accuracy in order to bolster various claims, or because failure is seen as a bug and not a feature.
Another reason why AI systems must fail is due to the tradeoff between exploration and exploitation. Some AI systems are able to learn from incorrect decisions in order to make better predictions over time. If the AI were not allowed to fail, it would probably make low-risk recommendations that were highly guaranteed to be correct. By failing and gaining information, AIs may make better, more informed decisions in the long-run despite early losses.
Corrective Systems
Modern AI systems have recognized the power of corrective design. When a user sees incorrect, irrelevant, or concerning content, they should be allowed to take action (see Clarification). The more natural this corrective ability, the more often users will interact with it. For example, in a ranked list of recommendations, perhaps allow users to re-order to content, dragging one item way down or pushing a hidden gem up. This allows users to see your AI as a tool of self-empowerment, rather than a blunt instrument. In addition, the AI does not have to necessarily use this information for further training—corrective design can delight users in small ways as they gain the ability to remix tools to their liking.
Design Questions

Considerations
Corrective Design
Users should be able to correct errors in your system, as a form of manual relabeling, feedback, or reranking.
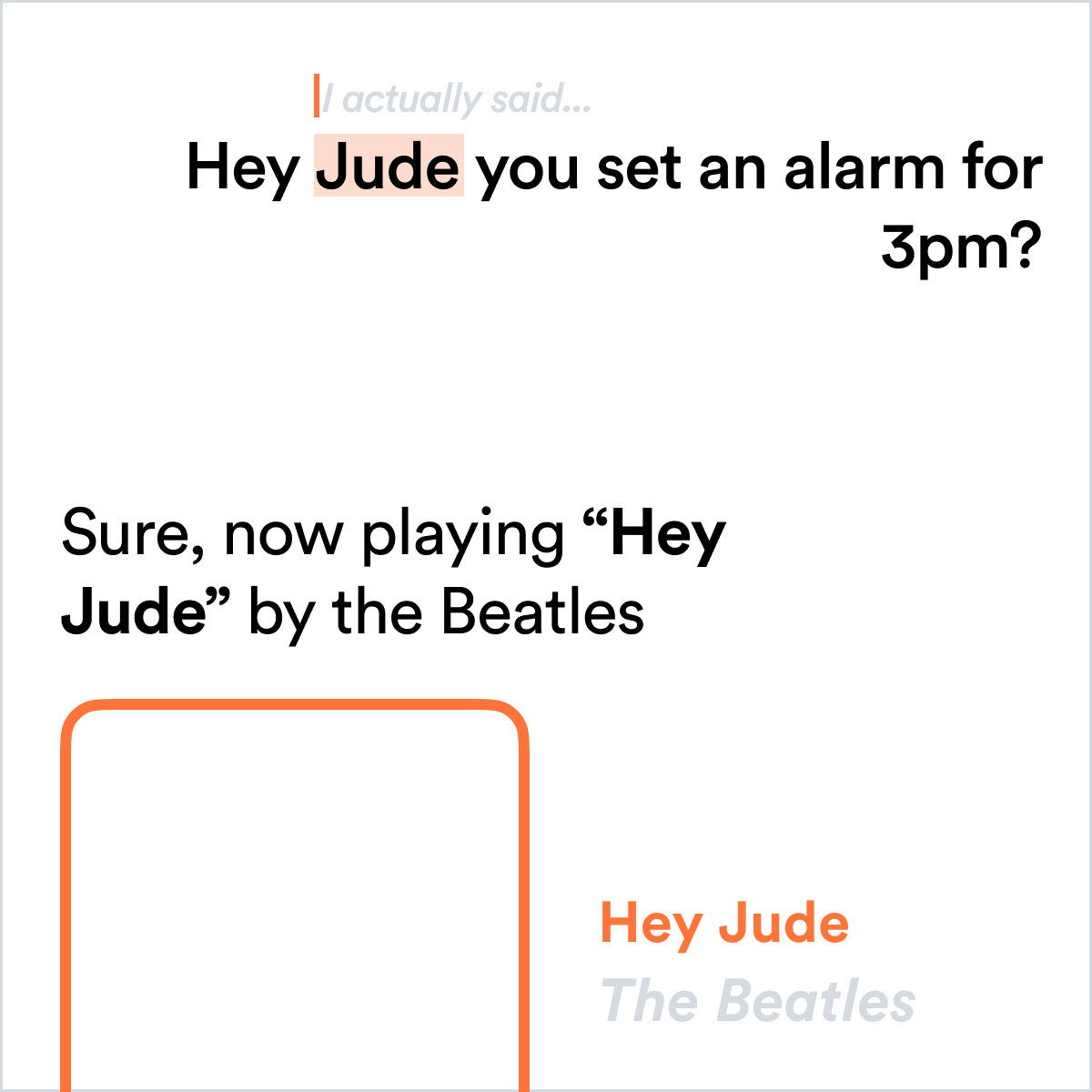
Open-Ended Systems
Any significantly open ended system will have the opportunity for awkward or even offensive output, for example text searches, image classification, even music recommendation.
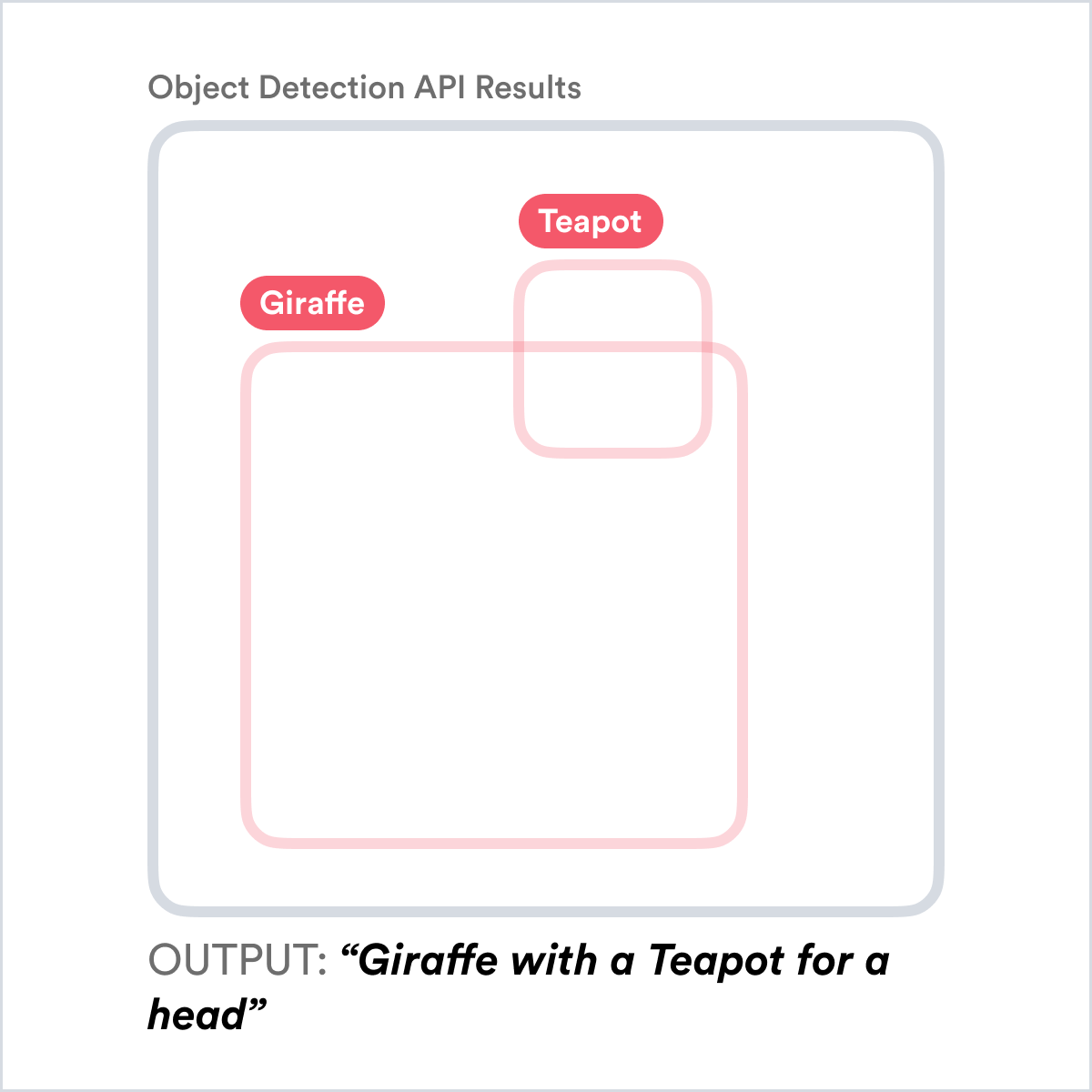
Forgiveness
Users tend to forgive errors of your system up to a point, as long as those errors can be reviewed or interacted with in some way.
Error Bounding
Systems that are designed as “end-to-end” learning systems are more unbounded and therefore more risky.
Accuracy
There is no such thing as 100% accurate for most AIs, for example in recommending a song.
Past Errors as Context
Surfacing past errors to the user may help them decide when to fully trust the system and when not to.
Ergodicity
Make sure users can’t get stuck when engaging in lengthy, multi-step interactions with an AI system.
Further Resources
- Failure Modes in Machine Learning jointly authored by Microsoft and Berkman Klein Center for Internet and Society at Harvard University
Footnotes
This idea is beautifully captured by statistician George Box’s famous aphorism, “all models are wrong, but some are useful”. ↩︎
