
Overview
There is no such thing as an un-biased AI, in the same way that there is no such thing as an unbiased person[1]. However, mitigating bias should be a core consideration of designing AI (and not for the sake of avoiding lawsuits). Bias is present in both the mundane and extreme cases, and certain biases may actually improve the user experience of your AI if designed well. Other biases could be extremely toxic, perpetuating harmful stereotypes and prejudices. Designers must play a part in unpacking the biases present in AI, and taking responsibility for the greater social repercussions of their products.
A bias is a tendency of a system to display an affinity towards certain kinds of decisions. Let’s take, as a non-AI example, a restaurant review catalogue. A restaurant review catalogue may end up seeming biased towards expensive restaurants, even if their reviews were only concerned with the uniqueness of entrées. This is because restaurants serving low-cost ‘standard fare’ would receive worse reviews, despite having potentially satisfied customers.
The above example suggests a few crucial things about bias—first, that a ‘bias’ does not always signify ‘wrong’ (just because good reviews are correlated with expensive restaurants does not make them necessarily unethical). In addition, it suggests that biases can emerge from seemingly unrelated design decisions. While certain biases may not hurt, or may even serve to benefit your users, other kinds of biases do relate to systemic harms and discrimination. Responsible, human-centered AI designers are aware of highly systemic biases in both a given product as well as society at large, as they make critical design decisions. Within AI, biases of all types can emerge in either data collection, in user experience design, or in the interaction between the system and its environment over time.

Bias in Data Collection
Biases observed in an AI are usually a result of the data the AI was trained with. Data by definition mirrors the world around us, including the social and cultural realities we live in. If your data is collected from a highly wealthy community, that data will mirror the inequalities of that wealth—the lifestyles, preferences, opinions, and habits that come with it. Most data collection strategies are unfortunately highly skewed towards certain population segments. To take a seemingly innocuous example, consider an online survey that you may want to send to a group of users. Responses to that survey are likely to reflect certain biases—more digitally proficient users, users with more time, users with stronger positive or negative opinions, users with better language skills, etc. Collecting data is tricky, as the phenomenon you are interested in may not even be easily measurable in the first place, requiring various compromises or inaccurate proxy metrics. Therefore, you must treat your data collection strategy as a design decision that filters down to the end user experience (see Problem Selection & Definition).
Even with a highly equitable and mindful data collection strategy, your data may still lead to completely unacceptable outcomes. This is because data-driven AI systems implicitly contain an assumption—that future decisions (predictions) should closely reflect past decisions (data). In systems of law, there are theories around ‘precedent’ and norms overturning past precents. However, AI systems largely lack this nuance, instead uniformly applying their data-driven precedents with mechanistic consistency. Always consider the fairness of past decisions as you apply data to make future ones.
Replaying Data Collection
Bias as User Experience
In certain ways, an AI’s biases are synonymous with that AI’s user experience. For example, a broadly multi-ethnic user-base may prefer a restaurant recommender that has the tendency to suggest various ethnic cuisines. In designing an AI, it often helps to list a set of positive biases that may be preferred by your users, in addition to a list of negative biases that may create harm over time. Many biases are extremely nuanced, and users may not be able to even describe them. But across large user-bases, these aggregate preferences will certainly affect your product. Do not relegate bias to an HR workshop—make it a core topic of conversation in your teamwork. The most successful products in the world have biases, sometimes extreme ones. However, a user experience may also exacerbate harmful biases through user experience, e.g. by disguising decisions to users as ‘data-driven’, or by only showing individual users a few results to prevent anyone from raising suspicion.
Complex Feedback Cycles
Unfortunately for designers, many biases may emerge from the relationship between a product and the social forces that surround it. Taking the prior example of a restaurant review catalogue, perhap good reviews from it lead restaurants to increase their prices. Therefore, even if reviewers were to produce their catalogue in a highly ‘bias-aware’ way with equal concern given to low- and high-cost options, users could still end up finding all of the highly rated restaurants are expensive! Recognize that not all biases are part of your individual design, but that bias is an ongoing question, since all products have an effect on the world around them.
Automated Bias Correction
Bias as Social Responsibility
Products and services do not simply passively exist in society—they actively create the social world we live in. In designing your AI system, you cannot simply ‘decide’ whether that system should affect society. If you ignore the social effects of your AI, you are implicitly affirming the status quo. While Lingua Franca does not espouse a specific perspective on social justice, it does recognize that many problems exist with the status quo of society. AI systems are likely to reaffirm the status quo, perhaps even more strongly than the human systems they replace, unless carefully designed end-to-end.
Design Questions

Considerations
Preference Bias
Systems that base decisions off of data gathered from other users’ decisions will mirror user biases.
Expressed and Revealed Preferences
Users’ expressed habits differ significantly from their revealed preferences, and recognize the bias in labeling data from one to inform the other.
Real vs Arbitrary Clusters
Sometimes an AI may cluster users into non-meaningful groups.
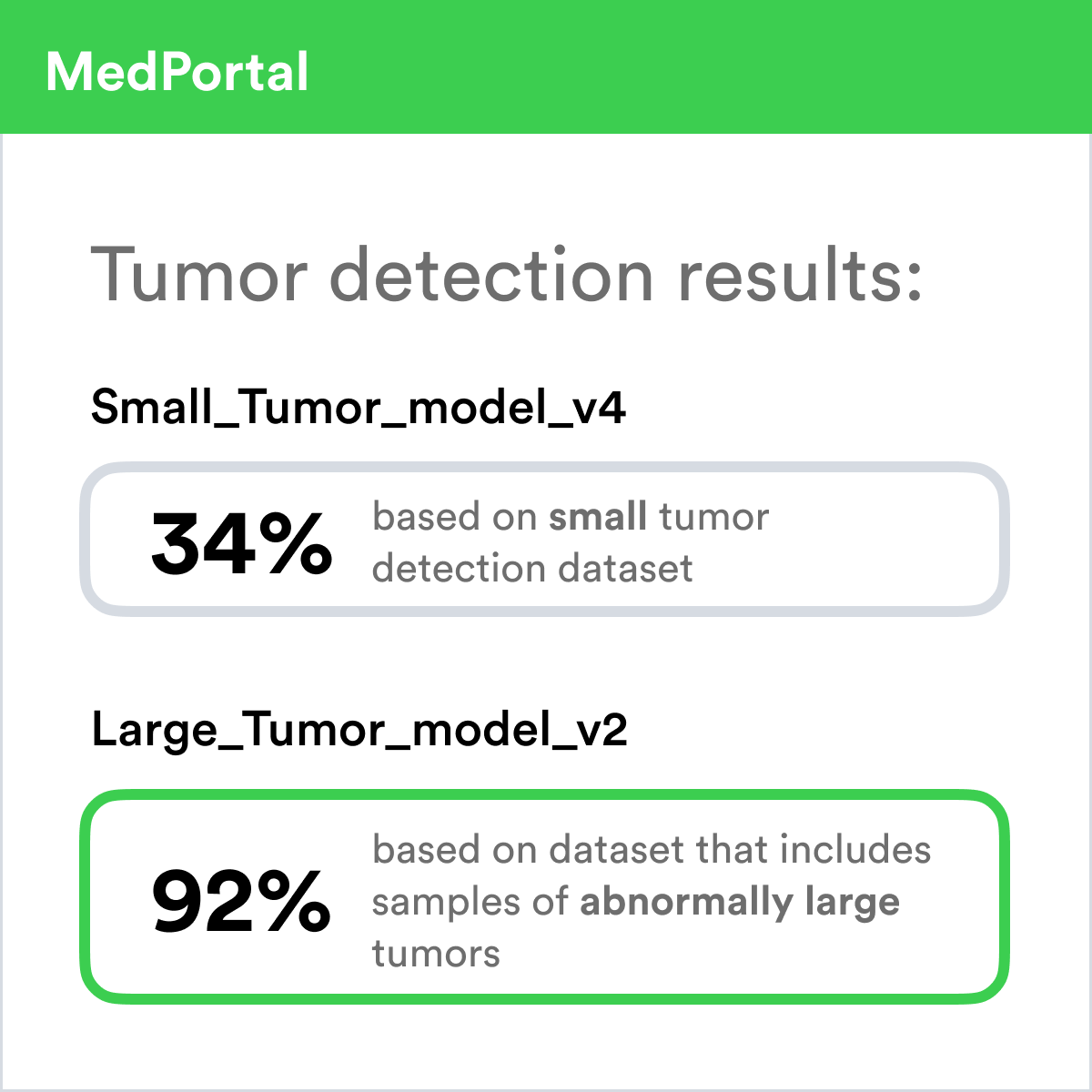
Comparative Bias
Providing differently biased models or AIs can give users a natural context and make relationships more decipherable.
Permission
Certain data is much better asked for, rather than inferred through indirect signals.
Further Resources
- How to Prevent Discriminatory Outcomes in Machine Learning by Global Future Council on Human Rights
- The Perpetual Line-Up: Unregulated Police Face Recognition in America by Georgetown Law Center on Privacy & Technology
Footnotes
For the purposes of Lingua Franca, we are not concerned with the purely statistical notion of bias (of an estimator). By bias, we are referring to its common interpretation as the subjective experience of prejudice. ↩︎
