Data Collection
While much of what has preceded sounds like a typical design research methodology, AI requires that additional time be spent collecting and exploring data. In fact, such an activity may make up the bulk of work in your overall product cycle. It is extremely important to design a data collection strategy as early as possible in the design process (see Architecture) in order to gain a realistic perspective on what is possible. More often than not, the data you seek to collect is not possible to collect directly. For example, the most reliable way to determine a house price would be to find the most recent bid by a buyer, but this information is usually private. Instead of relying on a specific kind of data, you may need to create an initial strategy, then iterate upon it until you have something tractable.
Labeling and Construction
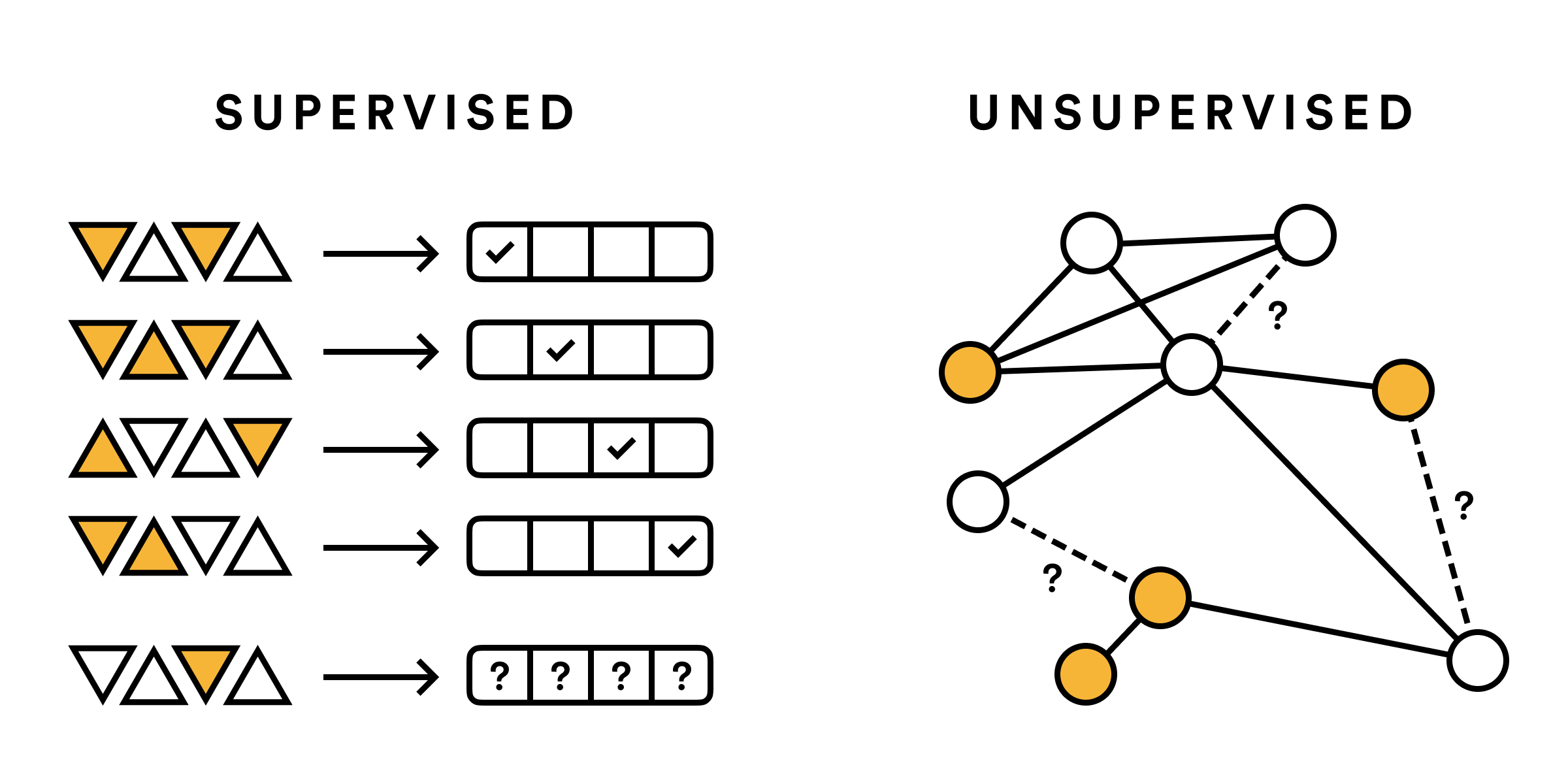
Often, an existing dataset cannot be used as is. It must be labeled with the action that you would like the AI system to predict. You will likely have to design an interface so that you can easily collect these labels. However, some AI systems do not require labels. To help identify when a label-based (called supervised) or a label-free (unsupervised) system will solve your problem, consider whether the questions of your AI system have a ‘correct answer’. Examples where there is a correct answer are: image classification, speech-to-text, and most statistics. These problems require that you feed the AI with examples of past ‘correct answers’, so the data needs to include that. Examples where there are no correct answers are: recommendations, text generation, and artistic tools. In these cases, the data does not need to be explicitly labeled.
Authentic and Synthetic Data
The best data is authentic—it comes from messy, real-world environments. Despite all its practical challenges, authentic data generates the most robust models. On the other hand, many researchers have attempted to generate synthetic data in the lab so they do not have to suffer the costs of real-world data collection. These include Gaussian process models[1] and 3D simulation tools like Habitat[2]. While useful in research, be careful with such tools, as the models they generate will display excellent accuracy in the lab while largely failing to translate that accuracy into real environments.
Visualization and Exploration
Once you gather a potential dataset (or perhaps you already had access to one), it is extremely important to confirm that the data is describing what you intended it to. Go back over the collection methodology and perhaps even replay the data collection process in your team. In a heterogeneous environment such as a hospital, different people may document the same exact situation differently. If this is the case, the data could lead to various unpredictable outcomes later on (see Dynamics). For large-scale data collection efforts on platforms such as Mechanical Turk[3], you should be sure to try the data collection tasks yourself, remaining careful about certain cultural assumptions that won’t hold in other countries.
Context Dependence
Visualizing and exploring data allows you to create intuitive conclusions. You are not necessarily looking for individual errors or bugs in the data—AI systems are generally robust to small errors. However, you can use visualization to identify whether the data contains different assumptions from your own. A dataset of housing prices may use the square footage of the land rather than of the building itself, throwing off your strategy. More problematic are assumptions in the data that relate to external information, which allows biases to creep into your system (see Bias). Make sure as far as possible that your dataset doesn’t assume some external knowledge. In addition, reduce the number of variables (columns) in your dataset as much as possible to ensure that your resulting AI system doesn’t rely on unintentional factors. However, given all this, AI systems may still display errors and biases (see Errata). Remember, you must keep exploring and visualizing your data as you collect new information, even after your system goes online.
Footnotes
Gaussian Process on Wikipedia. Note that this is somewhat distinct from modeling a dataset as a Gaussian mixture model—by synthetic data we are referring to Gaussian models that are hand-generated to imitate natural variation. ↩︎
Habitat-Sim by Facebook Research ↩︎
Amazon Mechanical Turk. Also see Figure Eight, Scale, and Samasource (latter options untested by the author). ↩︎
